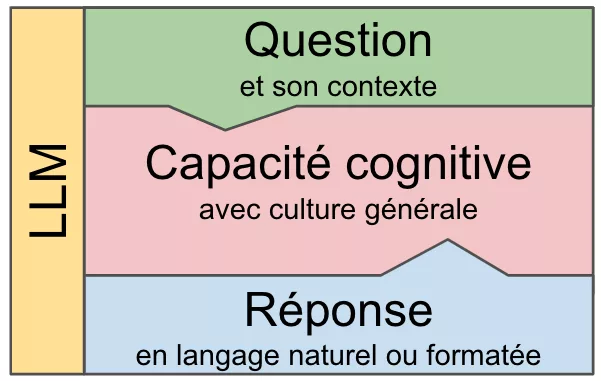
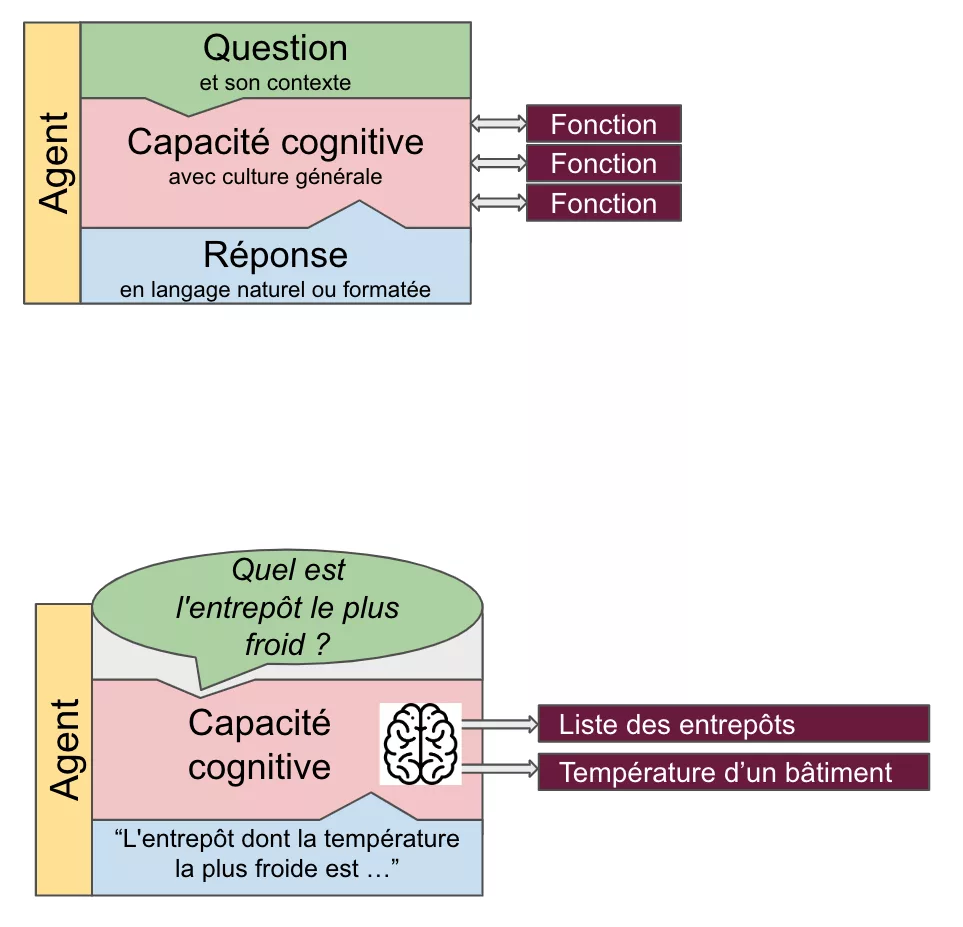
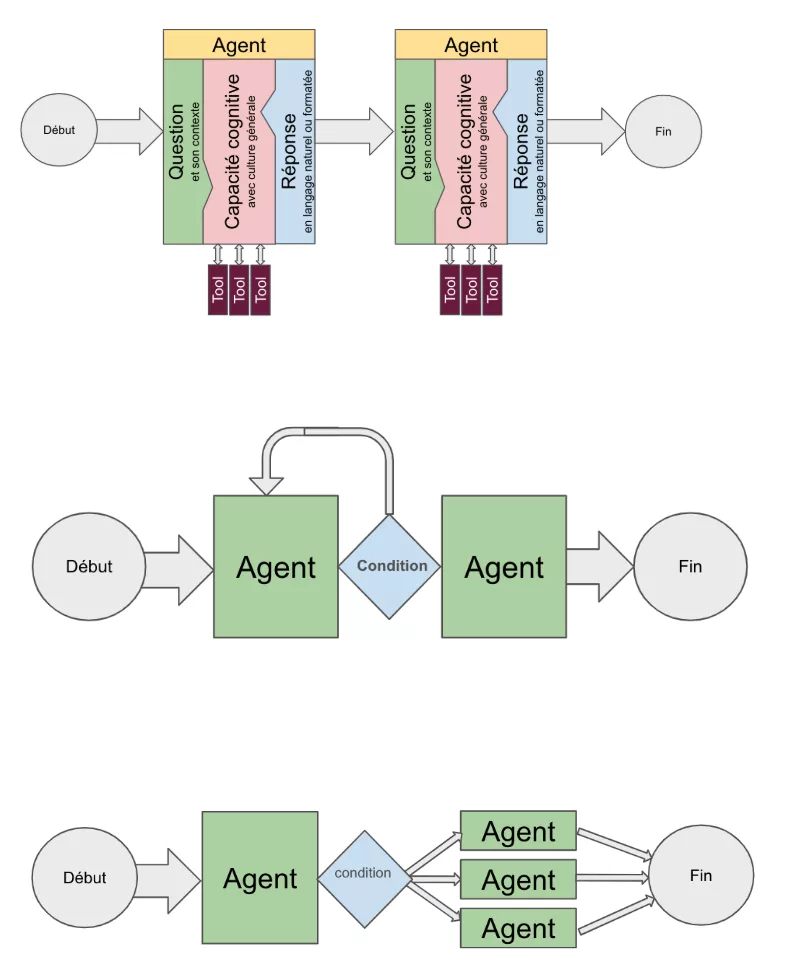
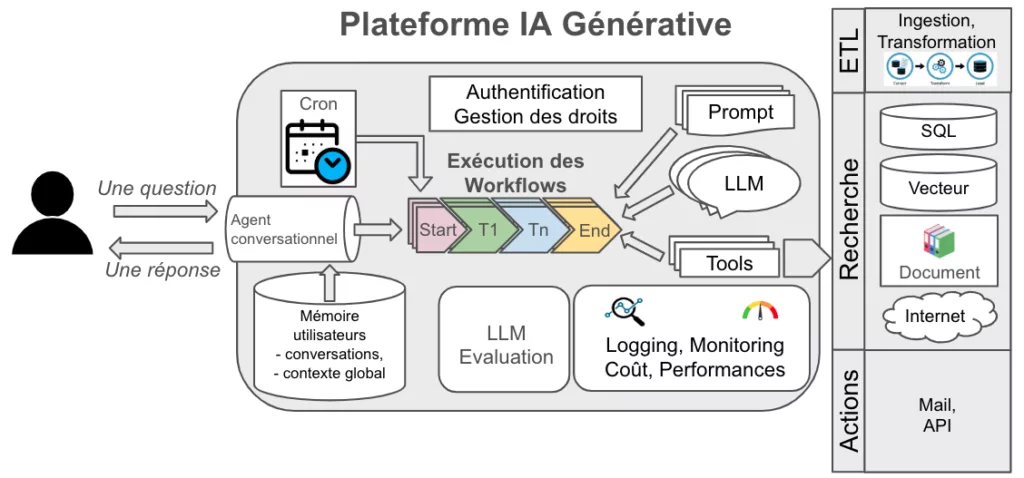
L’information est l’un des actifs les plus précieux d’une entreprise ✨, mais une grande partie de ces données reste inexploitable car enfouie dans des documents non structurés : emails, contrats, rapports, notes internes… Jusqu’à récemment, ces données étaient difficiles à organiser et à interroger efficacement.
Avec l’essor des modèles de langage (LLM) et des techniques comme le Retrieval-Augmented Generation (RAG), il devient possible d’automatiser l’analyse et l’exploitation de cette masse d’informations. Cependant, la mise en place de ces solutions ne s’improvise pas :
➡️ Quels outils choisir ?
➡️ Comment garantir la sécurité et la pertinence des résultats ?
➡️ Quels pièges éviter ?
Cet article vous propose une exploration pragmatique des possibilités et des solutions techniques permettant d’exploiter efficacement vos documents internes à l’aide de l’IA générative.
Concrètement, quel est ce potentiel ?
L’exploitation des documents non structurés par l’IA générative permet de :
- Mieux connaître ses clients et personnaliser l’offre
- Capitaliser sur l’expérience et les savoirs de l’entreprise
- Accélérer la recherche et la prise de décision
- Améliorer la gestion administrative
- Anticiper les problèmes à venir
Il est possible, par exemple, de poser des questions en langage naturel comme :
- Question support client : « En analysant les mails internes, les litiges, les remboursements et les forums publics, pouvez-vous analyser les tendances dans les retours clients sur les 6 derniers mois ? »
- Question support interne : « Quels sont les problèmes internes récurrents mentionnés dans les rapports d’incidents techniques ? »
- Question juridique : « En analysant nos documents juridiques internes et les nouveautés réglementaires sur le site de l’administration, quels sont les changements réglementaires que nous devons prendre en compte ?»
- Question sur la capitalisation du savoir de l’entreprise : « Quels sont les principaux experts de l’entreprise sur la technologie X et où puis-je trouver des exemples de leur travail ?»
- Commerce : « En analysant les réponses aux appels d’offres envoyés par la société ces 2 dernières années, quels sont les éléments utilisables pour construire la réponse à l’appel d’offre en pièce jointe ? »
- Question RH : « En tant que collaborateur de l’entreprise, quelles sont les règles concernant les congés exceptionnels ? »
- Question contexte commercial : « Quels sont les derniers échanges avec [nom du client] sur le projet X ? »
Mais comment mettre en œuvre concrètement ces solutions ?
Chaque jour, de nouveaux outils apparaissent, toujours plus puissants. Comment identifier les produits vraiment pertinents ? Comment organiser leur intégration dans l’entreprise de manière cohérente et sécurisée pour l’ensemble des collaborateurs ?
Certains outils sont cantonnés à des utilisations individuelles et gèrent très mal la sécurité et l’évolution. D’autres paraissent très simples mais sont finalement très complexes à mettre en œuvre. Comment s’y retrouver et mettre en place une feuille de route réaliste ?
Des solutions individuelles sans programmation
Pour commencer, les produits les plus efficaces tout en restant simples sont par exemple :
- NotebookLLM de Google
- ChatGPT Projects d’OpenAI
Le principe est, dans un premier temps, de télécharger sur un serveur un ou plusieurs documents, comme par exemple des fichiers PDF concernant les procédures RH de l’entreprise. Dans un deuxième temps, il suffit de poser des questions en langage naturel sur les informations contenues dans ces documents.
On peut demander, par exemple, « Quelle est la procédure pour demander une formation ? » ou « Quelles sont les dernières règles concernant le télétravail ? »
La mise en œuvre est immédiate, mais c’est une démarche individuelle qu’il faut relancer à chaque évolution des documents.
Des solutions automatiques avec très peu de programmation
Pour des besoins récurrents et plus complexes, il est possible d’automatiser les traitements. Les outils à envisager sont par exemple Zapier, Make, ou n8n. Ils permettent, sans programmation, uniquement avec la souris, d’enchaîner des appels d’outils connectés aux données de l’entreprise (mail, gestion de projets, base de documents, CRM, ERP…) avec des traitements LLM d’analyse ou de génération de texte.
On peut par exemple :
- Se connecter à un outil de gestion de projet comme Trello ou Jira pour extraire des informations sur un projet client, se connecter à une application interne via API pour obtenir des informations complémentaires, extraire les informations importantes et les anonymiser grâce à un LLM, et les rendre accessibles grâce à un chatbot.
- Sur réception d’un mail client, analyser la demande avec un LLM, rechercher les éléments demandés dans différentes applications, rédiger un mail de réponse et l’envoyer en brouillon au responsable du client.
Pour les plus téméraires, les possibilités d’automatisation sont énormes. Cependant, la difficulté apparaît quand les enchaînements de traitement se complexifient. Ces traitements sont difficiles à maintenir et à faire évoluer. La sécurité peut vite être fragilisée et la réutilisation à l’échelle de l’entreprise est difficile.
Des solutions centrées sur les LLM et la recherche vectorielle
Avec les LLM est arrivée une nouvelle possibilité pour capturer le sens des phrases, le traduire en représentation numérique et le sauvegarder dans des bases de données facilement interrogeables. C’est ce qu’on appelle les bases sémantiques ou vectorielles.
On peut, par exemple, numériser un roman entier, en petits morceaux (chunks), dans une base vectorielle et retrouver tous les passages où « le héros exprime des doutes » ou les passages où « le héros court un risque ».
C’est bien plus puissant que les solutions précédentes qui permettaient de faire des recherches uniquement sur des suites de lettres ou des mots-clés.
Un nombre important d’outils sont alors apparus pour faciliter la manipulation des LLM en fonction de leurs spécificités, la gestion des prompts pour questionner le LLM et la recherche dans des bases vectorielles pour retrouver des informations en fonction de leur sens. Des boîtes à outils ou frameworks se sont constituées pour construire facilement des solutions avec tous ces outils, comme par exemple LangChain, LlamaIndex, Haystack, Ragflow.
Ces solutions permettent en particulier de mettre en œuvre une architecture très puissante dans les solutions de recherche documentaire qui combine les LLM et les bases vectorielles, c’est le RAG (Retrieval Augmented Generation).
Deux approches pour exploiter les documents non structurés
Deux stratégies très différentes se dessinent aujourd’hui dans le développement d’applications à base d’IA générative exploitant les documents non structurés en entreprise :
1️⃣ Automatisation classique avec un usage limité des LLM
Si le projet repose principalement sur l’enchaînement de traitements et l’accès à diverses sources de données, mais que l’intelligence artificielle n’est qu’un complément, les outils d’automatisation comme Zapier, Make ou n8n sont généralement plus adaptés. Cette approche est pertinente lorsque les besoins se concentrent sur la structuration et la circulation des informations plutôt que sur leur analyse sémantique avancée.
2️⃣ Approche centrée sur les LLM et l’analyse sémantique
Si le cœur du projet repose sur des requêtes complexes en langage naturel, des recherches de similarités ou encore la synthèse d’informations, alors des frameworks spécialisés comme LangChain et LlamaIndex sont plus appropriés. Ces outils permettent d’exploiter pleinement les capacités des LLM en intégrant des bases vectorielles et en optimisant les interactions avec les données non structurées.
Des solutions robustes pour toute l’entreprise
Quand on passe de quelques applications développées par des utilisateurs avancés à des applications utilisables par l’ensemble des collaborateurs, il faut changer d’approche. Des solutions adaptées à l’ensemble de l’entreprise doivent pouvoir proposer un ensemble de services minimum que l’on trouve plus difficilement dans les outils d’automatisation simples :
- La mutualisation des projets (réutilisation de sous-ensembles de fonctions, gestion des versions)
- La garantie de performance en fonction du nombre d’utilisateurs (scalabilité)
- La gestion centralisée de la sécurité (autorisation et contrôle des droits d’accès)
Commencer par des solutions sans programmation sur le cloud et les faire évoluer
Les grands éditeurs proposent des solutions très simple pour démarrer. Google propose par exemple Vertex AI Agent Builder qui s’appuie sur toutes les briques habituelles de ses services cloud avec une intégration maximale des fonctionnalités d’IA générative. En quelques clics, on peut construire une solution dite RAG (Retrieval Augmented Generation) : on sélectionne les documents concernés dans le cloud de l’entreprise et après quelques paramétrages rapides, on peut intégrer l’outil de question-réponse dans des pages existantes du site interne existant, permettant à tous les collaborateurs de questionner cet ensemble de documents.
Il est beaucoup plus facile, avec cette solution, d’enrichir l’application avec des fonctionnalités plus poussées. L’intégration automatique des briques techniques du cloud permet à la solution d’être nativement robuste, sécurisée et évolutive.
Renforcer la chaîne d’ingestion documentaire dans des bases de données est un bon investissement
Avec l’évolution de l’entreprise, le nombre ou la variété des documents à prendre en compte augmente. La nécessité de les transformer d’un format à un autre augmente aussi, comme par exemple l’extraction de texte depuis des images (OCR). Concevoir une solide chaîne de transformation des documents est primordiale, ainsi que la mise en place de bases vectorielles performantes.
Lorsque les recherches dans les documents non structurés s’étoffent, il peut être aussi intéressant d’intégrer une base de graphes, comme Neo4J, pour modéliser les connexions et dépendances entre les concepts ou entité, ce qui améliore la génération de réponses pertinentes.
Et la confidentialité des données ?
Lorsque l’on manipule des informations internes à l’entreprise, la sécurité est cruciale. Il est tout à fait possible de construire des solutions 100% internes où aucune information ne sort de l’entreprise, même lors l’utilisation du LLM.
Cependant, l’utilisation de services sur des clouds mutualisés (SaaS) est plus facile et plus souple pour la mise en œuvre de nouveaux cas d’utilisation. Une bonne approche est peut-être de commencer par des solutions SaaS pour valider la pertinence des applications avec des données non stratégiques et ensuite, une fois le périmètre fonctionnel et la charge établis, de basculer sur une architecture complètement locale avec les données sensibles de l’entreprise.
Pour aller plus loin
Si l’exploitation des documents non structurés représente un premier levier de transformation, il ne faut pas négliger l’importance des données structurées. Les approches comme le Text2SQL permettent d’interroger directement les bases de données via le langage naturel, ouvrant la voie à une exploitation plus fluide des informations métier.
Par ailleurs, l’automatisation des processus grâce aux agents IA représente un second axe stratégique : en orchestrant l’interaction entre différentes sources de données et en exécutant des tâches complexes, ces agents permettent de fluidifier et d’accélérer la prise de décision au sein de l’entreprise.
Ces thématiques feront l’objet de nos prochains articles.
Conclusion
Les entreprises regorgent de documents non structurés sous-exploités. Grâce aux LLM et aux techniques comme le RAG, il est désormais possible de valoriser ces informations pour améliorer la prise de décision et mieux exploiter le savoir interne.
Cependant, la mise en œuvre ne s’improvise pas :
✅ Il faut choisir les bons outils en fonction des besoins réels et du niveau de complexité souhaité.
✅ La sécurité et la gouvernance des données doivent être une priorité dès le départ.
✅ Une approche progressive permet de tester rapidement des solutions sans engager immédiatement des ressources lourdes.
Que vous soyez une PME ou un grand groupe, l’exploitation intelligente de vos documents non structurés peut vous offrir un avantage concurrentiel considérable.
Vous souhaitez évaluer le potentiel des LLM pour votre entreprise ?
Contactez-moi pour discuter des premières étapes et identifier la meilleure approche pour vous.