Mes réflexions sur la construction d’un assistant conversationnel ou chatbot sur mesure.
Les chatbots, un outil indispensable pour les entreprises
Le chatbot est bien plus qu’un simple outil dédié au service après-vente. Il constitue le point d’entrée de tous les services d’IA de l’entreprise.
Le mode conversationnel est souvent plus efficace pour interagir directement avec le système d’information (SI) de l’entreprise que la manipulation d’une série de fenêtres et de listes déroulantes.
Par exemple, un collaborateur peut demander ‘Quels sont les derniers chiffres de vente ?’ plutôt que de naviguer à travers plusieurs écrans pour obtenir la même information. De plus, les assistants IA peuvent traiter des requêtes complexes en combinant plusieurs sources d’information, ce qui réduit le temps passé à rechercher manuellement des données.
Progressivement, toutes les applications intégreront une interface de dialogue avec une IA.
Maîtrise de la confidentialité des conversations
Les informations échangées dans les conversations avec les chatbots sont généralement très confidentielles. Maîtriser la conception de l’outil permet de mieux contrôler les flux et d’éviter que des données sensibles ne quittent l’entreprise.
Le ‘sur-mesure’ pour s’adapter aux spécificités de l’entreprise
Les chatbots doivent être finement adaptés à chaque entreprise. Les solutions standardisées, conçues pour répondre à tous les besoins, offrent une multitude d’options qui nuisent à la simplicité de l’application. Les solutions spécifiques permettent de mieux répondre aux besoins et de les faire évoluer.
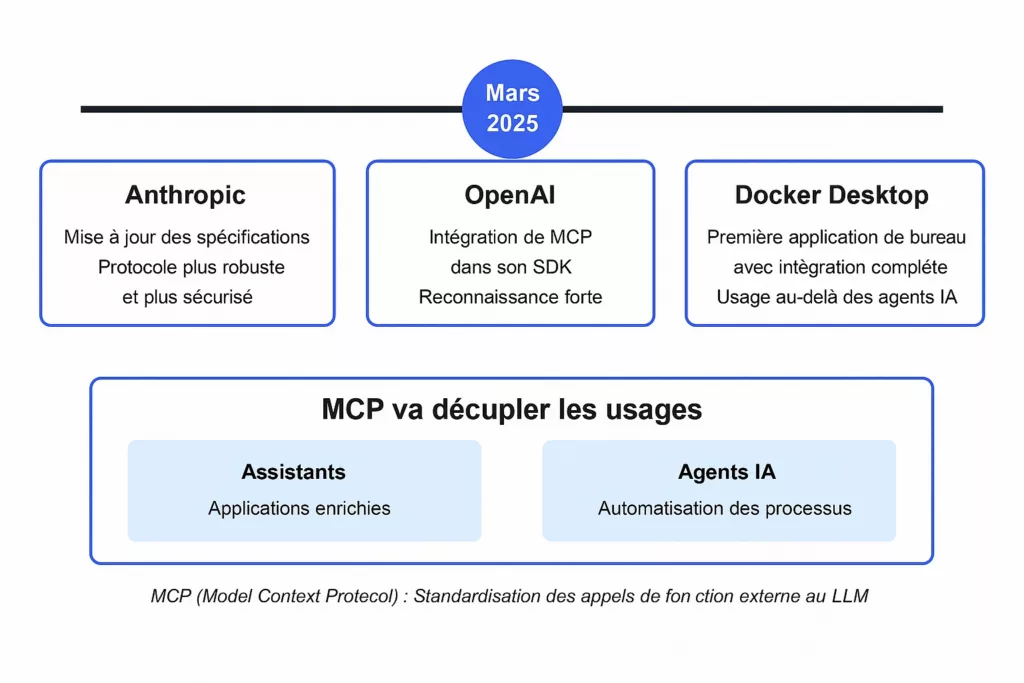
Chatbot, LLM, Agent, Assistant, Workflow IA, précisons les termes
Un agent IA est un LLM capable de solliciter des services techniques de l’entreprise (grâce à Model Context Protocol).
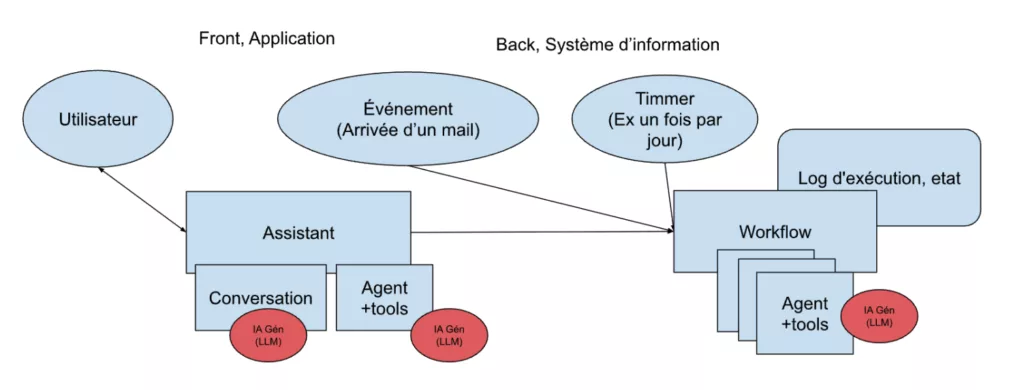
Le chatbot, en plus de gérer la conversation en langage naturel, intègre un agent et devient alors un Assistant IA.
Pour des traitements IA plus sophistiqués, il faut enchaîner les agents dans des workflows agentiques.
Quelles sont les fonctionnalités d’un bon chatbot ?
À l’origine, un chatbot se limitait à envoyer des questions à un LLM et à maintenir la liste des échanges précédents. Progressivement, d’autres services se sont ajoutés, comme la recherche sur le web ou la lecture de documents PDF (RAG).
Un chatbot d’entreprise efficace doit proposer un ensemble de fonctionnalités :
- Pouvoir choisir le LLM le plus adapté en fonction du type de travail à effectuer, avec éventuellement l’appel de LLM interne à l’entreprise ou propre à l’utilisateur.
- Offrir des outils de gestion des historiques de conversations avec une mémoire à long terme pour maintenir des contextes utilisateurs à injecter dans de nouvelles conversations.
- Proposer un espace de stockage de documents personnel en mode sémantique pour enrichir les conversations (RAG personnel).
- Permettre à l’utilisateur d’enrichir l’assistant avec de nouvelles fonctions externes standardisées (MCP).
- Proposer une bibliothèque de prompts prédéfinis à intégrer dans les échanges.
Le chatbot doit également intégrer des services techniques tels que :
- Un mécanisme de validation par l’utilisateur de certaines propositions de l’agent (Human In The Loop).
- L’appel de workflows externes à l’assistant, conçus par exemple avec N8N ou Langgraph Platform.
- Le comptage des tokens utilisés lors des appels au LLM, pour maîtriser les coûts.
- Des briques de code haut niveau telles que assistant-ui, react-langgraph, pour accélérer le développement de l’interface utilisateur en gérant facilement les conversations, la notion de Stream ou les artefacts de Claude.
Une fois les fonctions d’un chatbot idéal identifiées, comment le construire ?
Il existe de nombreux projets de chatbots en open source. Pourquoi ne pas partir d’un projet bien structuré et l’enrichir ? Après avoir exploré plusieurs options, j’ai identifié trois applications intéressantes, mais chacune ne couvre qu’une partie des fonctionnalités recherchées.
Lobechat (lobehub.com/fr)
Un chatbot très complet, bien architecturé, intégrant un RAG personnel. Cependant, l’interface est peut-être trop complexe et le système d’ajout de fonctions externes est propriétaire. Ajouter un client MCP semble peu aisé.
y-gui (github.com/luohy15/y-gui)
Un chatbot très simple qui intègre un choix de LLM et permet à l’utilisateur d’ajouter ses propres services MCP. Les composants principaux sont présents pour construire diverses applications. Cependant, il est très structuré autour de services cloud spécifiques (Cloudflare).
Assistant-ui-stockbroker (github.com/assistant-ui/assistant-ui-stockbroker)
Un démonstrateur qui met en valeur des briques techniques permettant de construire rapidement une interface utilisateur centrée sur les conversations : assistant-ui, Vercel AI SDK et des composants de réponse IA dynamiques (react-langgraph). Il illustre notamment la fonction “Human In The Loop”, permettant une validation utilisateur lors de l’exécution d’un Workflow IA. Cependant, le projet est exclusivement orienté vers des workflows nécessitant LangGraph Platform.
Le chatbot pour l’entreprise est encore à inventer
Les possibilités des LLM et des agents évoluent rapidement. Les fonctionnalités à intégrer dans un chatbot d’entreprise ne sont pas encore totalement stabilisées. Il reste de nombreuses bonnes idées à explorer pour concevoir des assistants vraiment adaptés aux entreprises.
Les entreprises qui investissent dès maintenant dans un chatbot sur mesure, bien aligné avec leurs besoins, bénéficieront d’un avantage compétitif significatif : des collaborateurs plus performants et une sécurité des échanges maîtrisée.
Et vous, êtes-vous aussi à la recherche du chatbot idéal pour votre entreprise ? Comment l’imaginez-vous ?